
Data past
You finally got marketing to agree that you need to check the email domain source. Back-end eventually got to your ticket and the pixel is firing. Analytics is capturing. You are ready to launch your A/B test! “How long do you want to run it?” “I don’t know, like two weeks? How long did the last one take to get that p-value?” [Data scientists pound head here.]
You are p-hacking. P-hacking is running tests until a p value dips below .05. Wait, isn’t it supposed to be under .05? Actually, no. And yes, I did try to teach you that in my statistics class while you were texting your boyfriend.
Data present
The p-value (“alpha”) refers to the likelihood that the A and B differ significantly at the moment, but that difference is not real (or replicable). Every time you get a new sample, you get that chance at a mistake. When you check the p-value with every sample, instead of checking once at a predetermined number of samples, you gave yourself (# checks * .05) risk instead of .05 risk. Knock it off. P-hacker!
The other side of this equation is the 1- value (“beta”), referring to the likelihood that the test will be able to detect a real difference between A and B.
Alpha and beta are equally important in A/B testing, but power is often ignored. There is nothing magical about p<.05 or power>.80. Those cut-offs are just conventions, and we are their weak little sheep. If you think “This test is really important, if we make this change unnecessarily, we could really tank our business”, you might consider setting alpha to .001. If you think “Haha, I wonder if putting dog LOL in the emails will increase clicks on the trucker jobs?”, you might consider dropping alpha to .1 (translated: who cares if you’re wrong, dogs are awesome).
And what, pray tell, do these ramblings have to do with sample size? Power is determined by sample size and effect size. See this sweet RShiny app to get an intuitive feel for how they are related. Think of it this way: if the difference between A and B is real, but very small, you are going to need a huge sample to be able to see something that tiny. On the other hand, if the effect is huge, you will be able to see it quickly with many fewer samples. For example, if you offer to sell pineapple juice at 50% off, you can guess the difference between the original price (condition A) and the 50% off price (condition B) is likely to be very large. You do not need to waste a bunch of time and money sampling to figure this out. If you sample me, I will buy your entire stock, because pineapple. However, good luck knocking 50% off the kale. Well, except here in Santa Monica, because we gotta have our kale.
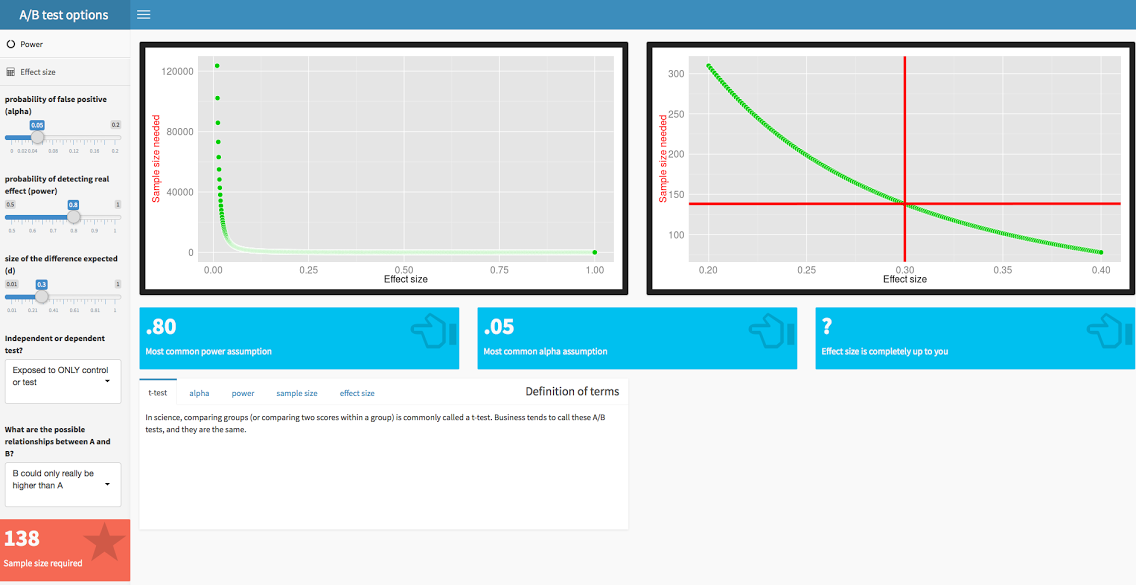
Wait, now you are bringing up “effect size”? That’s like dating for two months and suddenly mentioning that you have a kid. What is this “effect size” you speak of?
Effect size is the size of the expected difference between A and B. For A/B tests, the most commonly used effect size is called a Cohen’s d. Don’t you dare capitalize that, it’s little d. (The big D, don’t mean Dallas, is divorce from Mark Chesnutt.)
Well, crap, how do I know what that the effect size is for my A/B test? You might not. You can decide how big of an effect size would make you care. If you only want to act on “big wins” in A/B testing, you might only act if the effect size was large. If you work in an extremely tight market where every point counts, you might want to act even on small effects.
However, there are ways of calculating effect size if you know a little about the size of the difference that you are expecting. Our effect size calculator will give you an intuitive feel for how effect size changes.
If you fancy, you can use software like PASS to really specify the crud out of your test to determine sample size. If you want a standalone, G*Power is the freeware go-to and favorite of scientists everywhere. The tools here are powered by R (library pwr), and we sure would appreciate a shout out if you use ours (citation below).
Data future
By the way, this is old news. Stats change dramatically and totally have fashion trends too (Brentwood, I’m talking to you!). If you are just using t-tests without power analyses, you are so 1906. There have been decades of statistical developments. Consider these to up your A/B testing game, in order of things-you-should-have-done yesterday.
- General linear model
There is no reason you should only test two conditions (A/B). Test 3. Test 4. Heck, if you have enough samples test 30! GLM is the non-monogamy of statistics, no need to limit to two.
- Bootstrapping
Skewed distributions gotcha down? Wait, what? You weren’t even checking? Oy vey. Consider bootstrapping to sample across distributions of the test statistic rather than the sampling distribution.
- Bayesian
Two academic journals now prohibit frequentist statistics. Frequentist, by the way, is the class of statistics under which A/B tests fall. They make fun of us so hard. And they should, because we keep p-hacking. One answer to the problems with frequentists is Bayesian. MCMC=TRUE does not make you Bayesian. Learn it. Live it. All the kids are.
Nicole Prause, Ph.D., is a ZipRecruiter Data Scientist
Citation (APA style):
Prause, N. (2015). Two-sample power and effect size calculator. [Software]. Available from https://liberos.shinyapps.io/power/




