
Preparing and ingesting Druid databases from Delta Lake tables on Amazon’s S3 cloud – the nuances you need to know.
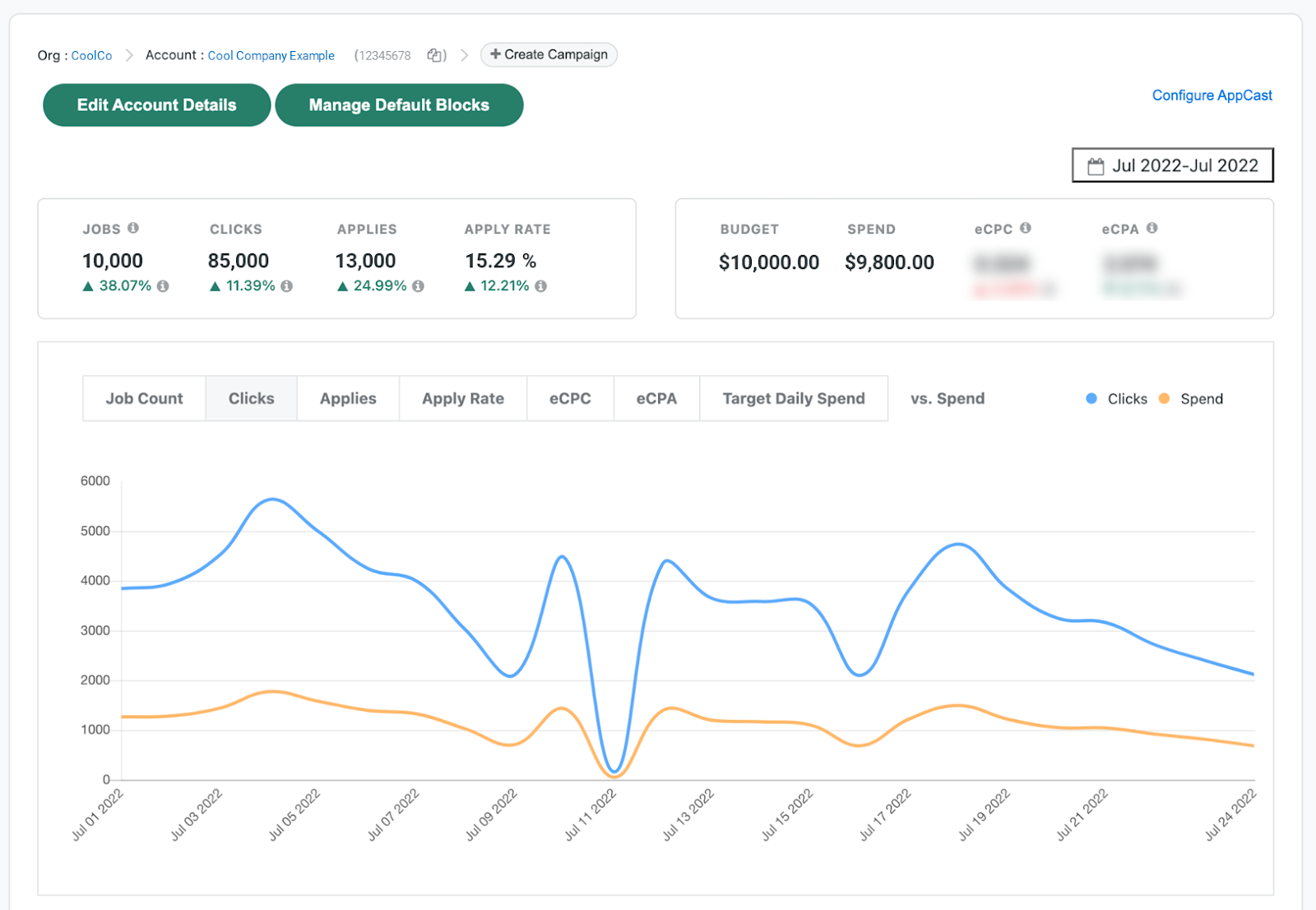
On my team at ZipRecruiter we manage the online BI reporting dashboards for thousands of enterprise employers and agencies. Our web UI (Fig. 1) provides these businesses with important information about job seeker engagement with their open positions using comparative graphs, trends and statistics to relate budget and spend to views, clicks and applies.
In our initial version, data came from MySQL DBs which weren’t very well optimized for the use case. As a result, the dashboards would frequently fail to load or crash, particularly when attempting to pull large chunks of data over long time ranges.
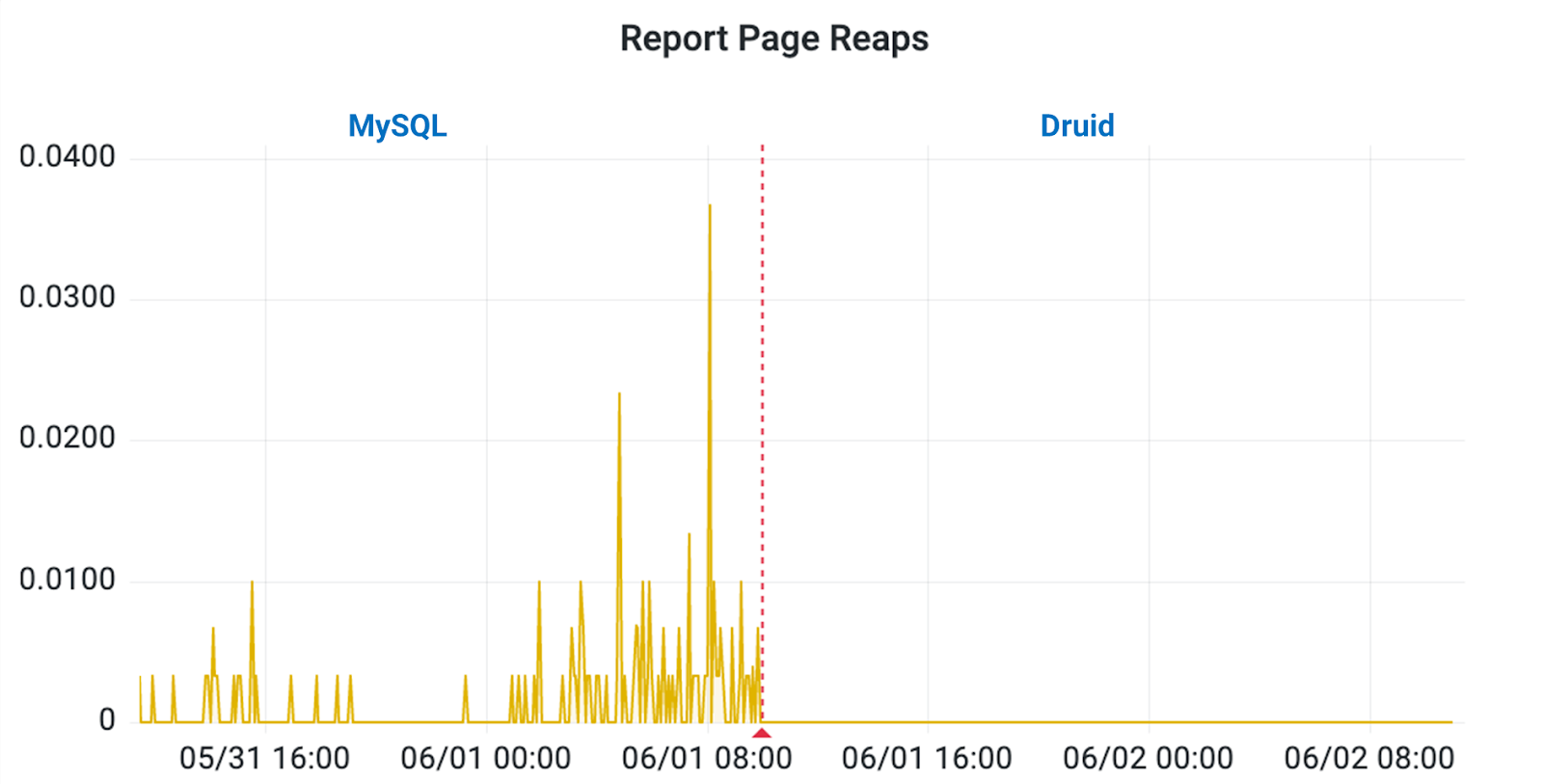
After some investigation, we decided to convert these databases to Druid, which completely revolutionized the dashboards’ performance and user experience. Figure 2 shows load times for some of the pages in our dashboard. Although this is the entire HTTP request and not just the database query, it nevertheless reflects how well these pages are working. The red line in the middle denotes the day we switched from MySQL on the left to Druid on the right. Loading became much more stable and consistent, allowing us to handle a wide variety of data and still return a response in a reasonable amount of time. What’s more, once we switched to Druid, the need to cancel page requests and queries running over our time limit has been nearly eliminated (Fig. 3).
In this article I’ll cover the key aspects of Druid relevant to this type of use case and explain the nuances of prepping and ingesting your data into Druid from Delta Lake.
Druid is optimized for time series aggregations
Druid is a distributed database optimized for aggregations over time series data. It does this fast enough to be suitable for real-time user-facing workloads, like a web UI dashboard.
‘Time series data’ refers to events or observations happening over successive time instances. A single event, such as a click, apply, or page view can have multiple identifier attributes (like click ID and campaign ID), user specific attributes (like an IP address) and a full-resolution timestamp (date, minute, seconds and so on). As this data accumulates over time, the database gets bigger and bigger.
‘Aggregations’ refer to a manipulation or combination of raw event data over a certain range into a value that is more useful and insightful. For example, one type of aggregation are ratios like ‘impressions per placement by day’ or ‘job titles per location’. Aggregations also include calculations like sums, averages, or percentages; for example, ‘total applies during a specific week in a campaign’ or ‘the percentage of applies from total views’. In dashboards and queries, these aggregations or ‘rollups’ are very common.
While Druid is well suited to storing raw event data and aggregating in real-time, for this project we chose to ingest pre-aggregated data into Druid. We already had a system, built using Scala on Spark, that aggregates and denormalizes revenue data, along with data from other systems, into tables optimized for reporting, and then saves them using Delta. Ingesting these existing tables into Druid means that we can choose which database is best suited to each use-case (Druid for real-time, Delta for batch) while using the same familiar schema. It also overcomes Druid’s biggest limitation: Joins.
Druid can only ingest and store the data that you feed to it. This means it cannot actively collect or combine what it has with other data from other sources (aside from limited lookup operations). What’s more, in favor of efficiency, Druid has limited support for joins at the moment and prefers that all of your data be denormalized and merged prior to ingestion.
Now that we understand what Druid is best suited for, let’s roll up our sleeves and bring Druid into the world of Delta Lake and S3 cloud storage.
Pointing Druid to the most recent Parquet file in Delta Lake
Before we can start ingesting our data, we need to understand a little bit about Delta Lake. In this context, think of Delta Lake as a layer of partitioning and metadata on top of Parquet files that are stored in S3 (or other object storage). Although Druid can easily read Parquet files, it is not equipped to read the metadata or manage the partitions that Delta Lake creates. To point Druid to the right data we wish to use requires a basic understanding of Delta table structuring.
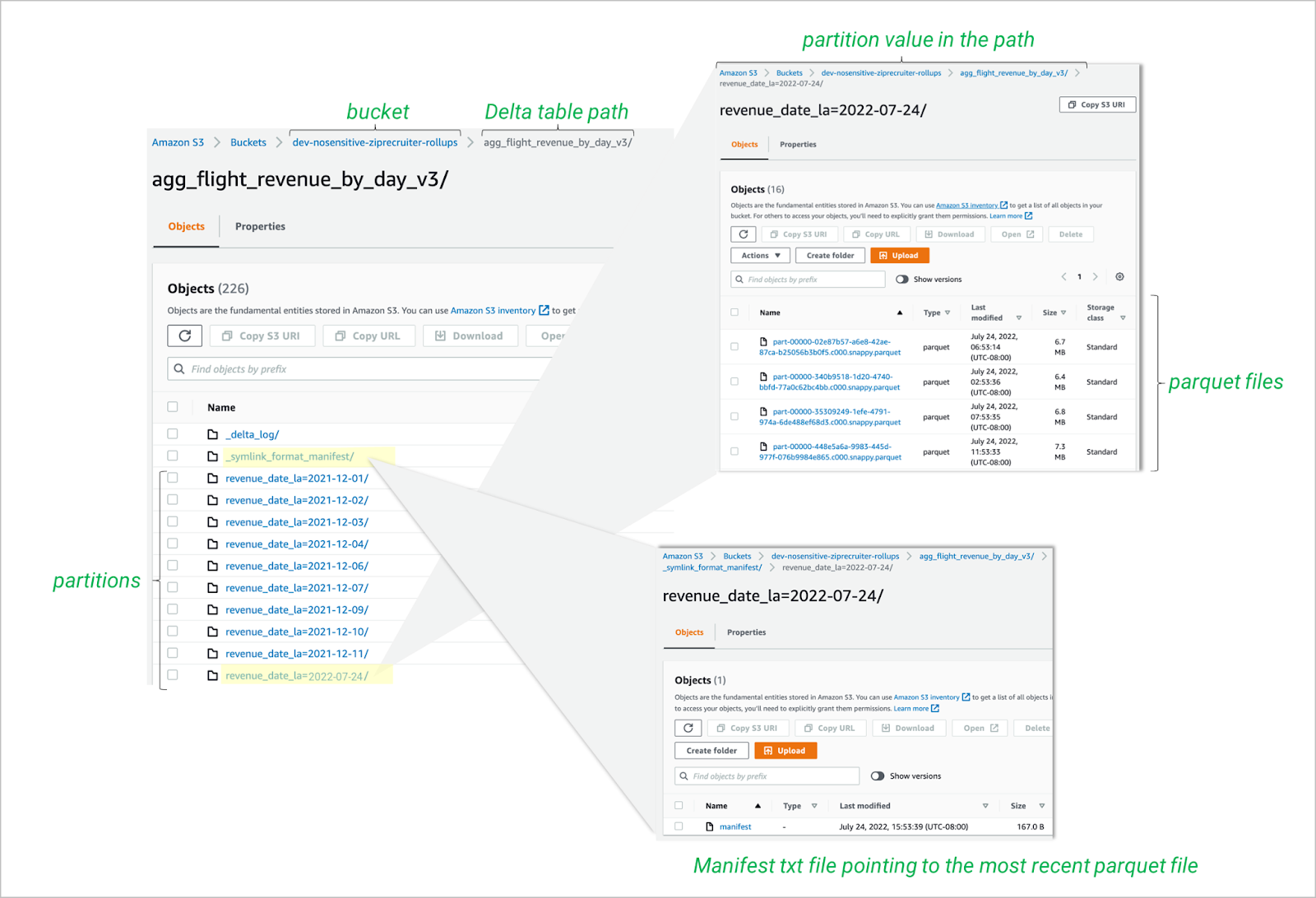
Within a particular S3 bucket, and a particular table path, you will find a list of partitions. Within those partitions are the Parquet files (Fig. 4).
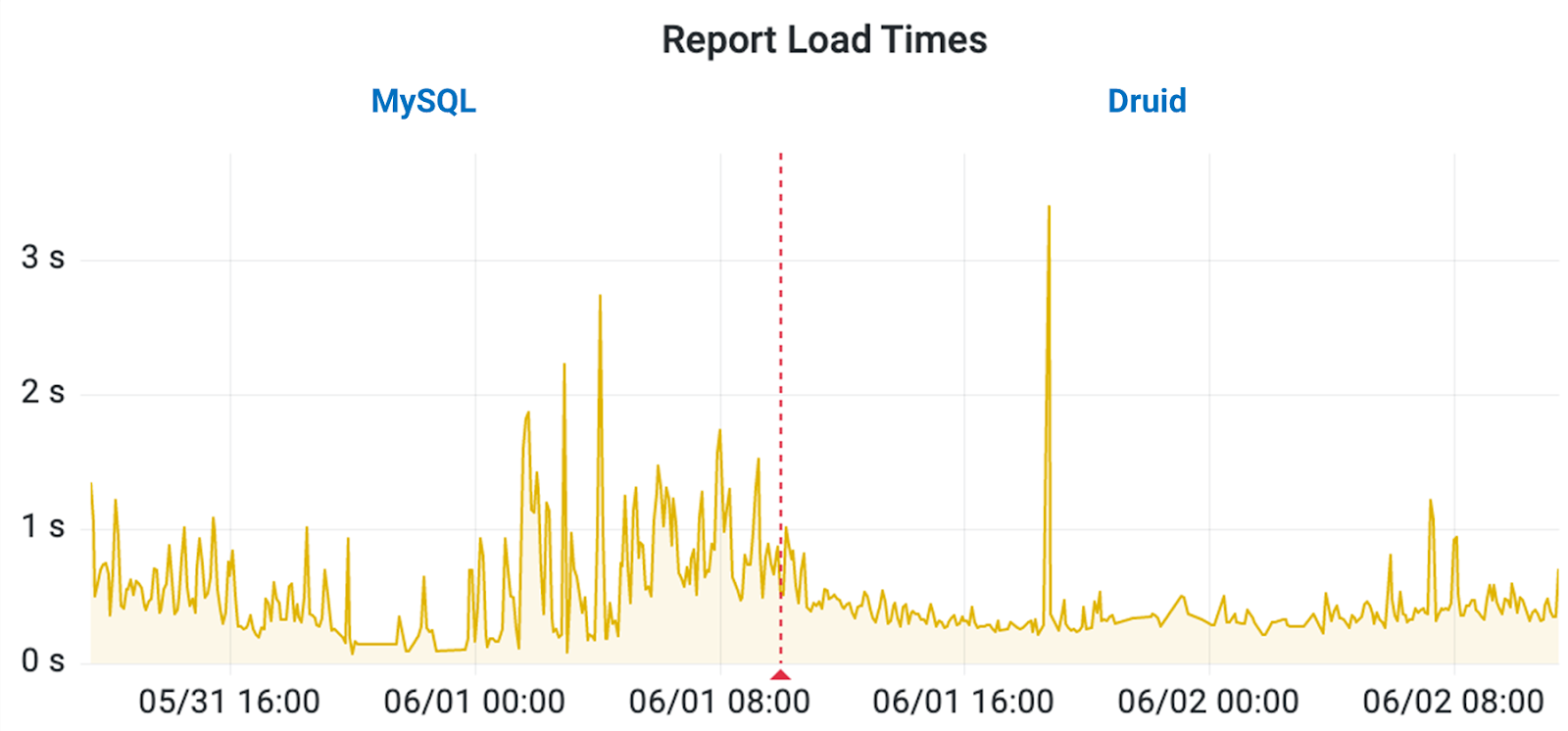
Fig. 4: Finding the path to the most recent parquet file in each partition
The first challenge is that the partition column value is stored in the S3 path itself and not actually stored at all in the Parquet file. When Druid reads a Parquet file, it won’t have access to this column value.
The second challenge is that there might be multiple Parquet files in a single partition. This can happen for two reasons. Delta will split a partition into multiple files if the amount of data in it becomes too large. In addition, Delta saves old versions of files until you vacuum them. We, for example, have a process that runs every hour, reprocessing data from the prior 24–48 hours, and overwrites the old partitions. Every hour a new, fresher file is created. This results in new parquet files being created every hour.
To find the most recent Parquet file(s) follow the _symlink_format_manifest/ path into the relevant partition. There you’ll find a single manifest file which lists S3 paths for the latest parquet file(s).
Timestamps are critical for ingesting data
Druid supports a limited set of data types which include longs, floats, doubles and strings as well as some “complex” statistical approximation types. Most importantly, for the purpose of successfully working with Druid, are timestamps (stored as Unix epoch milliseconds) and a special timestamp called __time.
Because Druid is optimized for time series data, every single table in Druid must have a __time column. This is critical. If Druid can’t find a value for the __time column, it will not ingest your data.
So, what column can we use for the __time? If we were ingesting raw event data, we would have an “event time” timestamp that we naturally map to Druid’s concept of __time. However, we are ingesting aggregated data and the event time is the dimension that we have aggregated into a simple date. This column is also our partition column which, as previously mentioned, is not available in the parquet file. Because Druid is not going to be able to read the partition column, before writing the data we duplicate the partition column so that it will be stored in the parquet. Druid can find this duplicate copy of the column when it reads the parquet file. During our implementation and roll-out, we’ve found that this solution has some downsides. The duplicate column can cause confusion and it means that existing data, without the duplicate column, cannot be ingested as-is. An alternative solution is discussed later.
Time intervals in Druid
Most queries in Druid will be filtering your data using an interval between two moments in time. Intervals are also used during ingestion. Druid uses the ISO-8601 time interval format, made up of start-time/end-time, where the start-time is inclusive, but the end-time is exclusive; meaning the end-time is not included in the range. This is useful for capturing whole months. By choosing the first day of the next month as the end-time you can ensure you don’t miss that pesky 31st… or was it 30th?
Another useful Druid shortcut relates to intervals. Instead of a specific end-date, we can describe a duration using ISO 8601 duration representation: P1M for ‘period one month’ or PT1H for ‘period of time one hour’. For example, 2023-07-01/P1M or 2023-07-01T12:00:00Z/PT1H.
Getting Data into Druid – Batch vs Stream Ingestion
To ingest data, Druid uses ‘append’ or ‘replace’ methods, rather than ‘insert’ and ‘update’. For example, it is possible through batch ingestion to replace the data for a certain month with a new set of data. Because Druid doesn’t have any sort of scheduler, when we want to trigger an ingestion we typically use the Apache Airflow data pipeline orchestrator.
Another option is stream ingestion, implementable with Kafka, for example. We decided not to use stream ingestion, mainly because Druid would only have the data that’s on the stream, meaning it would not be denormalized nor enriched unless we did live stream enrichments.
Writing a Druid ingestion spec in JSON
An ‘ingestion spec’ is a JSON file that tells Druid where your data is, what it looks like and how to store it. Here is a typical basic version (explanations follow):
{ "type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "s3",
"uris": [ "s3://bucket/path/file.parquet" ]
},
"inputFormat": {
"type": "parquet",
"binaryAsString": false
},
"appendToExisting": false,
"dropExisting": true
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "dynamic"
},
"maxNumConcurrentSubTasks": 100,
"maxRetry": 10
},
"dataSchema": {
"dataSource": "agg_flight_revenue_by_day",
"granularitySpec": {
"queryGranularity": "day",
"rollup": false,
"segmentGranularity": "day"
},
"timestampSpec": {
"column": "_druid_time",
"format": "auto"
},
"transformSpec": {
"transforms": [
{
"type": "expression",
"name": "is_open_flight",
"expression": "if(is_open_flight == 'true', 1, 0)"
}
]
},
"dimensionsSpec": {
"dimensions": [
{
"name" : "campaign_id",
"type" : "long"
},
{
"name" : "flight_start_date",
"type" : "long"
},
{
"name" : "daily_click_rev_usd",
"type" : "double"
},
{
"name" : "currency_code",
"type" : "string"
},
...- appendToExisting and dropExisting are set in a particular way that makes sense for our use-case, where, every hour we replace the entire data for the day. Depending on what your data processing is like, adjust those accordingly.
- dataSource defines our table. Note that Druid doesn’t have a concept similar to schema – everything is in one big database. So, be careful to name your tables reasonably so as not to interfere with others sharing your cluster.
- The granularitySpec section refers to the way that the data is stored. If you have data that’s getting updated every hour and you’re confident you’ll never query at minute resolution, you can optimize a little bit and store by the hour or day etc.
- timestampSpec is the crucial __time column mentioned earlier. Here you point to the time column which is the duplicate of our partition column.
- transformSpec is where we prepare or manipulate data for Druid. In this example we had a boolean column when Druid doesn’t support boolean. We simply translate it from ‘true’ or ‘false’ strings into 1 and 0, accordingly. To learn more about Druid expression language, refer to the documentation which is pretty straightforward.
- dimensionsSpec is where we get into our actual columns, our dimensions, specifying the name of the dimension and the type one by one.
Triggering a Druid ingestion event in Python
Without going into all the details, here are the key parts of the API (don’t blindly copy-paste this)
import boto3
import json
import urllib.request
from datetime import datetime
# Assume we are loading data for today
date = datetime.now().strftime('%Y-%m-%d')
druid_host = 'http://localhost:8888'
json_spec = 'path_to/ingestion_specs/tablename.json'
s3_bucket = 'bucket_name'
manifest_path = f'table_path/_symlink_format_manifest/partition={date}/manifest'
# Read manifest file from S3
client = boto3.client('s3')
response = client.get_object(Bucket=s3_bucket, Key=manifest_path)
manifest = response["Body"].read().decode("utf-8")
paths = manifest.rstrip().split('\n')
# Read in our ingestion spec json
with open(json_spec, 'r') as f:
contents = f.read()
spec = json.loads(contents)
# Fill in the path to our S3 parquet files
spec["spec"]["ioConfig"]["inputSource"]["uris"] = paths
# Tell Druid we want to overwrite the data for today's partition
spec["spec"]["dataSchema"]["granularitySpec"]["intervals"] = [ f"{date}/P1D" ]
# If a time column is not available in the parquet, Druid will use this value
spec["spec"]["dataSchema"]["timestampSpec"]["missingValue"] = date
req = urllib.request.Request(f'{druid_host}/druid/indexer/v1/task',
json.dumps(spec).encode(),
{'Content-Type' : 'application/json'})
# Add user/pass to basic auth headers if needed
# Submit the ingestion request
response = urllib.request.urlopen(req)
# You can also parse the response if you want to check the status of the task
First we connect to S3 to read the text contents of that manifest file. Then we simply split that by line to get a list of S3 paths for the parquet files we want to ingest.
Next, we parse the json ingestion file that we wrote earlier. Now, we can insert the updated values that are specific to the partition we want to ingest. The list of parquet URIs is used for our inputSource and we specify an interval, for today, telling Druid what range of data we want to overwrite.
And here comes the critical one, the timestampSpec/missingValue. In the case where Druid cannot find a timestamp column in your data, instead of failing the ingestion, we instruct it to use the date we provide here. This solution works well when processing one partition at a time and you don’t want to have the aforementioned duplicated column.
Finally, we can POST the updated json ingestion spec to the appropriate API on our Druid host.
Checking ingestion status with task_id
Druid’s ingestion function immediately returns a task_id which we can use to check the ingestion status. Tasks are usually surprisingly fast, but if you have lots of data it may take a few minutes. By pulling the Batch Ingestion API and querying the status of the task_id you’ll be able to see when a task finished and whether it was successful or not.
Overall we have found Druid to be extremely convenient, fast and reliable for managing our own exploration queries as well as those of our customers through the web UI.
If you’re interested in working on solutions like these, visit our Careers page to see open roles.
* * *
About the Author
Stuart Johnston is a Senior Software Engineer at ZipRecruiter. Currently on the Enterprise Performance Marketing team, he builds and maintains the databases that help employers manage their recruitment campaigns via sophisticated web UIs. During the past 8 years at the company Stuart has had the opportunity to design and ship logging systems, APIs and monitoring tools for a wide variety of internal and external stakeholders. Being part of a tight-knit group of elite engineers providing employment opportunities to anyone, anywhere is what keeps Stuart fueled with passion and a sense of purpose every day.








