
This article shares some insight into the challenges the ZipRecruiter Tech Team works on every day. If you’re interested in finding solutions to problems like these, please visit our Careers page to see open roles.
One of the interesting challenges that the ZipRecruiter Employer Data team faces is processing frequent changes to the corpus of tens of millions of jobs quickly, while still enabling fast and efficient reads for downstream processes that perform further data transformations or machine learning. One of the tools that we use to support this work is Apache Spark, a unified analytics engine for large-scale data processing.
Spark’s parallelism is primarily connected to partitions, which represent logical chunks of a large, distributed dataset. Spark splits data into partitions, then executes operations in parallel, supporting faster processing of larger datasets than would otherwise be possible on single machines. As part of this, Spark has the ability to write partitioned data directly into sub-folders on disk for efficient reads by big data tooling, including other Spark jobs.
With respect to managing partitions, Spark provides two main methods via its DataFrame API:
- The repartition() method, which is used to change the number of in-memory partitions by which the data set is distributed across Spark executors. When these are saved to disk, all part-files are written to a single directory. The reason for that is because this method doesn’t define the physical partitioning of the output, to do so we will need the following method.
- The partitionBy() method, which is used to write a DataFrame to disk in partitions, creates one sub-folder (partition-folder) for each unique value of the specified column.
In a recent project, our team’s task was to backfill a large amount of data (65TB of gzip json files, where file sizes were approximately 350MB) so that the written data would be partitioned by date in parquet format, while creating each file at a recommended size for our usage patterns (on S3, we chose a target size between 200MB and 1GB).
As we implemented this, we also wanted to achieve good wall-time performance while writing.
As we explain how we approached this, let’s first review the different uses of repartition and partitionBy.
First, let’s try repartition alone:
| df.repartition(15).write.parquet("our/target/path") |

15 files were created under "our/target/path" and the data was distributed uniformly across the files in this partition-folder. As we specified, Spark split the data into 15 partitions and allocated 1 task for each partition (assuming that the execution environment allowed it).
Now that we understand what repartition does on its own, let’s combine it with partitionBy. A straightforward use would be:
| df.repartition(15).write.partitionBy("date").parquet("our/target/path") |
In this case, a number of partition-folders were created, one for each date, and under each of them, we got 15 part-files. Behind the scenes, the data was split into 15 partitions by the repartition method, and then each partition was split again by the partition column. This is why we ended up with approximately 15 * N files in total (where N is the number of distinct values we have in “date”).
In our case, we had a total of 4 different dates, so Spark created 4 partition-folders, as shown below. The default naming scheme of the sub-folders is the partition column and its value as partition column=value.
date=20190313/
date=20190315/
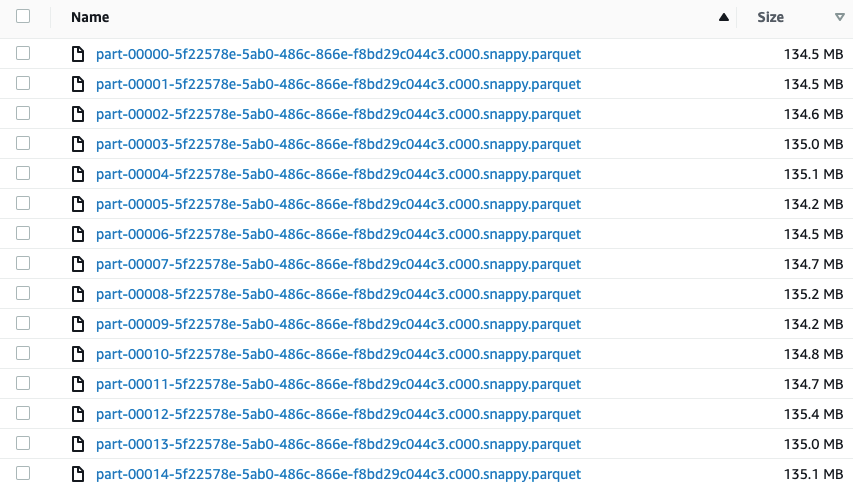
As we can see, the data distribution was significantly skewed and the partition-folder date=20190313 ended up with file sizes outside of our desired range. This shows that understanding the data is critical to writing data into partitions, since the way it behaves can influence our decisions about the number of files we want to produce.
We wanted to find a method that would give us more control over the number and size of files we produced. In other words, we wanted to provide the number of files we wanted and we are willing to accept the prerequisite that we know the typical size of records in our dataset.
In order to understand how we did this, let’s look at another repartition feature, which allows us to provide columns as parameters too:
| df.repartition(15, col("date")).write.parquet("our/target/path") |
This can be valuable because it enables us to control the data before it gets written. In this case, the data was split into 15 partitions, as before, but now each file can contain multiple values of the “date” column; different files won’t share the same group of values.
Another DataFrame API method, repartitionByRange(), does almost the same thing as the previous method, but it partitions the data based on a range of column values.
If we combine repartitionByRange or repartition with partitionBy using the same column as a parameter, such as below:
| df.repartitionByRange(15, col("date")) .write.partitionBy("date").parquet("our/target/path") |
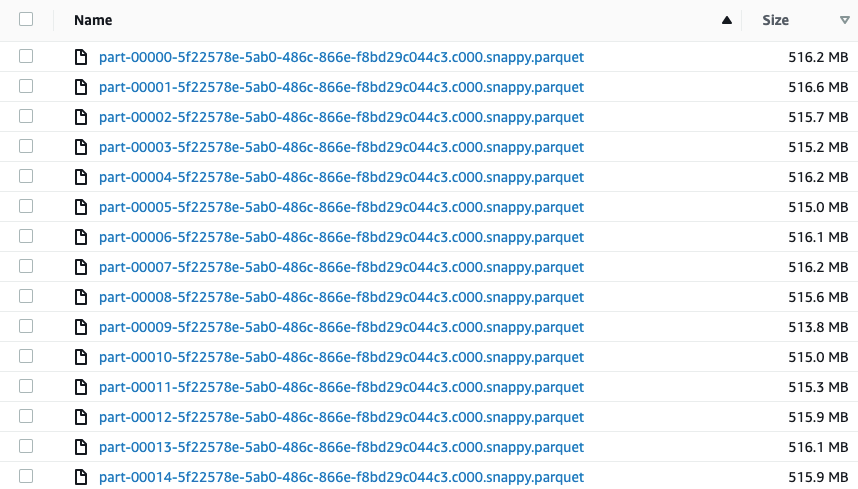
We end up with one fat file for each partition-folder:
date=20190313/

date=20190314/

date=20190315/

date=20190316/

Why did this happen? The repartition operation tried to create partitions with unshared “date” values between them, and all identical “date” values sit together under the same partition. In our case, there are only 4 date values, which is why the first argument of 15 is ignored. Only one file is created per partition when the partitionBy method writes the data into the partition-folders. This makes sense because the data was already partitioned by date by the repartition method.
One thing we considered at this point was to set spark.sql.files.maxRecordsPerFile, which would force a split once the specified number of records was written. However, this didn’t achieve one of our earlier stated goals of wall-time performance as it doesn’t increase parallelism.
Given this, we needed another way to repartition the data. We were not completely off on our first approach—we just needed an additional variation:
| df.repartitionByRange(20, col("date"), col("hash_id") .write.partitionBy("date").parquet("our/target/path")) |
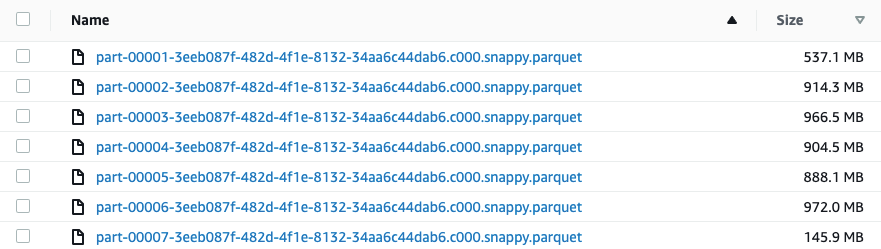
Our solution of adding a column of well-distributed hashed values did the trick and gave us the ability to choose the approximate number of files (called x, hereafter) we wanted for the output (in this case, at least the number of distinct values of date; we also switched partitions parameter to 20 to reduce file sizes to our desired range).
date=20190313/

date=20190314/
date=20190315/
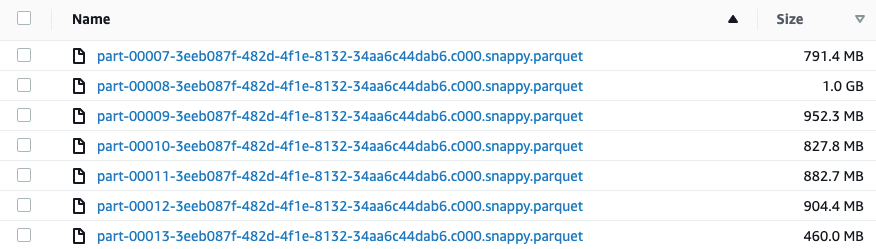
date=20190316/
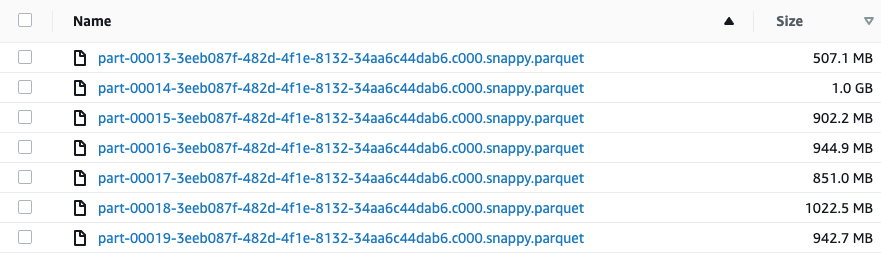
As we can see there are now almost no small files.
Why did this work? The split was done by date and the hash column which, together, were effectively unique. In addition, records with the same date generally appear ordered within their in-memory partition. Next, the partitionBy method was executed and wrote the data into the partition-folders. We ended up slightly more than x files in total (23 files) due to the fact that a partition may contain more than one date value and may need to be broken by the partitionBy method.
This set up partitions, which were written to partition-folders by their date values. Because they were already grouped by the date column, it was very easy for each one of them to become a data file without worrying about cases where there is more than one date value per partition. In other words, with this partitioning approach, most of the partitions were ready to be written just as they were – Spark didn’t need to rearrange the partitions or recombine them when partitionBy was called.
So, how do we choose a good x? This ends up being a process of estimation and sampling. Of course, it is better to perform tests earlier with less data (being distributed in the same way as the original) so that we waste less time on adjustments.
In conclusion, when writing partitioned data, we need to consider our various options and goals, along with our writing methods. These can have implications for how our data will be stored at the destination and the performance of the writing process.
This article shares some insight into the challenges the ZipRecruiter Tech Team works on every day. If you’re interested in finding solutions to problems like these, please visit our Careers page to see open roles.




