
This article shares some insight into the challenges the ZipRecruiter Tech Team works on every day. If you’re interested in working on solutions to problems like these, please visit our Careers page to see open roles.

From the Author
“I build data pipelines for ZipRecruiter’s marketplace, providing access to various applications and users. I love the diverse opportunities I have to grow at ZipRecruiter all while stepping out of my comfort zone and impacting people’s careers.”
— Or Bar Ilan, Big Data Engineer at ZipRecruiter.
Our mission at ZipRecruiter is to make the job search and recruiting experience as fast and effective as possible. To do so, having ultra-fresh, well-structured data in our data lake is crucial. This data is used for multiple tasks, like training ML models, making better business decisions, and monitoring the system’s health.
When a company reaches the scale of ZipRecruiter, a huge amount of data constantly streams in from multiple sources: job seekers, employers, 3rd party vendors, you name it. Our job stream, for example, amounts to about 15–20 thousand jobs per second, resulting in tens of millions of events per day for just this event type; and we have dozens of unique event types. To provide great service to our clients and users, we need to react in near real-time.
Unfortunately, the most popular off-the-shelf tool for handling data input to data lakes, Kafka Connect, doesn’t actually deal with structuring data or conveying each variable’s meaning, such as schema or validation rules at big data scales. So we had to create a tool that does and does it fast.
Why ultra-fresh data is so important
As in most big data environments, new data used to arrive in our data lake in batches, usually hourly. For some of our use cases once per hour simply wasn’t fast enough. It limited the kinds of solutions we could build.
For instance, before we publish a new job to the world, some processing must be done: we make sure it’s not spam, not a fake or unrealistic position, or that a few extra zeros didn’t slip into the salary offering by mistake. These processes work better using big data analysis backed by a data lake. Since our goal is to provide employers with great potential candidates for their job posts within one hour of uploading a position, a data lake pipeline that only provides an hourly freshness rate is not an option.
To further demonstrate why it is so important to have data resting in the data lake in a matter of minutes, consider the monitoring process of an A/B test. If a new buggy A/B test treatment caused ZipRecruiter’s systems to send out a triplet of identical emails to every job seeker, it could only be discovered via big data analysis. If relevant data is delayed by an hour, we wouldn’t be able to detect the issue, stop the A/B test, and fix it in time.
An in-house Kafka-connector to harness the power of Delta Lake
To enable high-speed data flow into our data lake we developed an in-house Kafka connector which we call Kafka2Delta (K2D for short). K2D consumes data from Kafka and writes it to our data lake using Delta Lake.
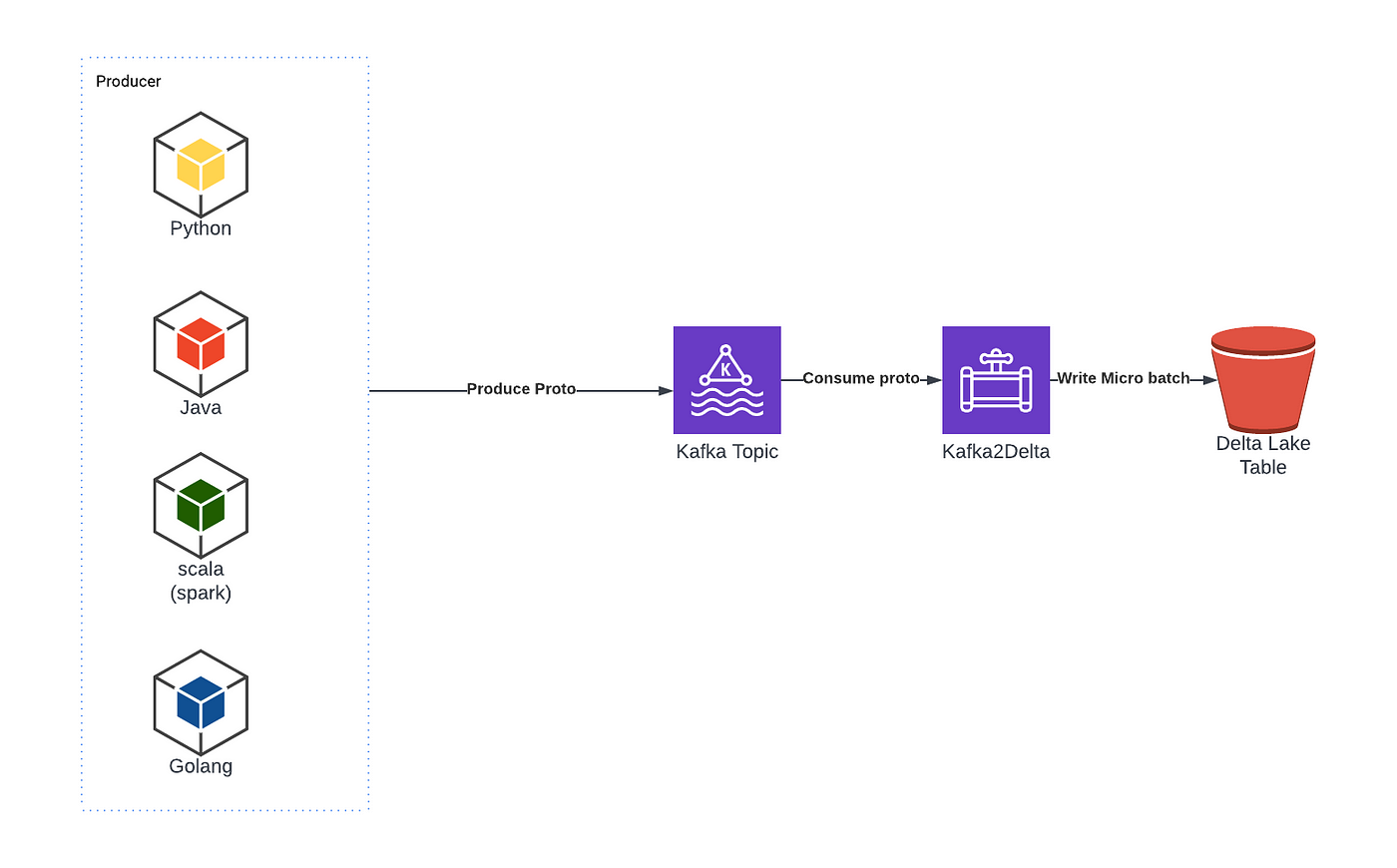
K2D is written in Scala with Spark and uses Spark-structured streaming. It consumes 1-minute micro-batches from Kafka and then writes the data to S3 as a Delta Lake table. Downstream Spark consumers can use Spark structured streaming to stream-consume the Delta Lake table and create derived data sets that also have minute-level freshness.
Our streaming Delta Lake tables are read-write optimized by compacting the data into hourly partitions. The benefit of Delta Lake in this context is that this compaction is safe and doesn’t cause conflict for concurrent readers. Without this compaction, in order to read the last week of data one would have to load ~10,000 small files (i.e. 60 minutes * 24 hours * 7 days a week) from S3 which is very inefficient and slow.

The challenge of dealing with schema
One of our key data engineering principals at ZipRecruiter is “data is like a radioactive material — valuable, but dangerous if not handled properly”. Collecting data without clear schema and documentation is a classic example.
We used to collect unstructured data from our backend as JSON events. For example, every job record has hundreds of fields, and the source of truth connecting field names to their meaning was a Google sheet. This was tolerable for a while, but as the engineering team grew and increasingly more people began using this data to train ML models and build new data pipelines on top of it, things became unmanageable. People were afraid to change their code because they didn’t know what downstream processes might break.
Building a formal schema suitable for big data work had to be part of the overall solution.
Enforcing a schema using protobuf
We built K2D to enforce a schema defined using the protobuf format. We chose protobuf for the following reasons:
- The use of protobuf is good practice when it comes to Kafka because it is an efficient binary format;
- We already use protobuf for the schema in other disciplines such as gRPC for backend, so it was already in our stack;
- Our Kafka connector needs to support schema evolution. Protobuf offers the mechanism for updating schema without breaking downstream consumers (except for omitting fields); and
- Protobuf is also consistent with the GitOps principle, enabling us to manage our schema’s version control.
This schema standardization alone has streamlined communication across our tech organization and made it easier to create new products and analyze their performance. Our lesson here is that creating a clear and up-to-date schema and documentation for your data from day one is critical for long-term success and totally worth the investment.
Monitoring with self-generating dashboards (yep, it’s a thing)
Monitoring is a core part of everything we do at ZipRecruiter. As part of the K2D system, we also created tools to monitor every component and incremental step in the pipeline — from Kafka, Spark, Delta Lake, and k8s — independently.
Our monitoring data collection and alerting system is Prometheus which feeds to our visualization system Grafana. Prometheus scrapes both the main K2D process and the exporters we internally develop to get metrics on components such as Kafka and Delta Lake tables.
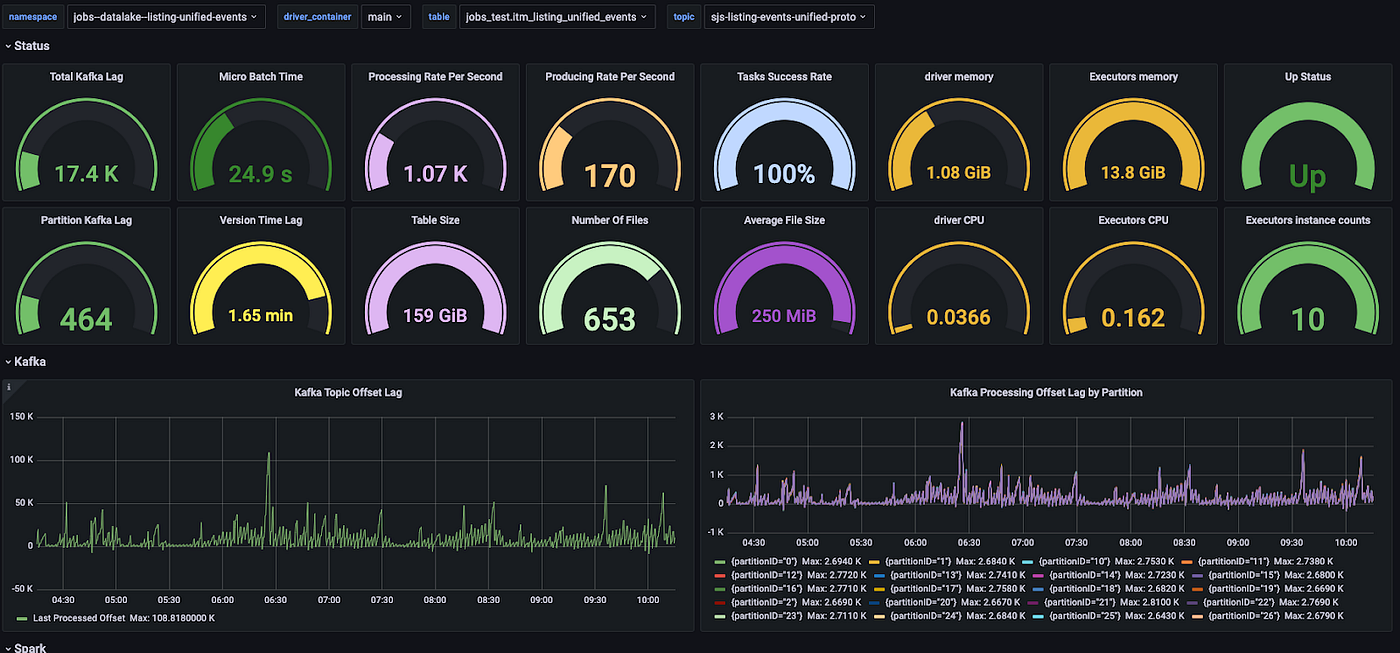
We learned that the most important thing to monitor is the Kafka lag — the difference in the Kafka offset between how much we write to Kafka and how much spark reads. This is so important because it verifies that K2D consumed all the data successfully. Kafka protocol is reliable, so it also means the data was written successfully by Spark.
Another feature of our K2D system is that whenever a new pipeline is created, performance metrics are automatically created. Grafana is set up to pull from new datasets like this and automatically generate new monitoring dashboards along with a standard set of alerts, such as when the Kafka lag is too high.
A good product has multiple use cases
Using K2D, teams can now easily create new pipelines with 1-minute freshness into the data lake subject to a clear schema. This sets the stage for developing new tools and services for our users based on data that is easy to use.
One of the use cases for K2D is a job posting. We can now ingest all our job postings to the data lake and process them in a matter of minutes. The clean data can be distributed for use in various systems and sent externally so that it can be indexed by search engines and Google For Jobs within minutes of the employer completing the listing, instead of what used to be a minimum of 60 minutes.
Another use case is job seeker personalization. We want our system to adjust the jobs it sends to individual job seekers based on their behavior. A simple example is not sending someone more than X job notifications a day, or if they haven’t opened our emails for Y days, scale back on the notifications. This is a part of our Personal Recruiter product, designed to make the ZipRecruiter user experience even more personalized.
Making these personalization decisions requires deep analysis of huge amounts of interactions describing the behavior of our job seekers, and doing so in a few minutes. The Personal Recruiter team managed to deploy a complete solution to production in just one week using a Golang producer and K2D, with big data tooling on top of the data lake for analysis.
Tips for a successful development cycle
K2D was a project that grew from the ground up. A bunch of us realized the need, and pitched it to management who ‘gave us the green light’. One of the most important leadership requests was to make sure that from the outset we had multiple use cases for the product.
This organically ensured all relevant parties were involved in the design process, and that they were also committed to using the product when it was ready.
After a few years siloed at home due to the pandemic, we also were delightfully reminded how useful ‘being’ in a room together is. We started the project working mostly remotely but it meant a lot of time wasted on offline Slack ping-pong. Once we all came together in one room at the office, we managed to finish and ship the project in a record 3-hour coding session.
About the Author
This article shares some insight into the challenges the ZipRecruiter Tech Team works on every day. If you’re interested in working on solutions to problems like these, please visit our Careers page to see open roles.




