
Fine-grained job title classification with noisy labels using the REINFORCE algorithm and multi-task learning
This article shares some insight into the challenges the ZipRecruiter Tech Team works on every day. If you’re interested in finding solutions to problems like these, please visit our Careers page to see open roles.
At ZipRecruiter, our smart matching technology helps millions of job seekers connect to their next great employment opportunity. Before the algorithms behind this technology can do any work, however, we need to ensure our important variables, jobseeker data (resume, profile) and job data (title, description, location), are classified according to a clean and logical taxonomy.
Every job has a title and a description given by the employer, but job titles come in many different forms. The terminology for one job title often varies across different industries and our users tend to include unique phrasing to describe a job.
Instead of “Data Scientist,” for example, an employer might publish a job with the title: “Looking for Data Scientist with Python experience in Los Angeles, CA.”
Job titles are also complicated by the occasional typo or because of keyword spamming. Both of these introduce even more variability which has the potential to compromise the quality of a match.
To resolve this issue, we built a taxonomy title database. As you can imagine, one of the greatest challenges we face is classifying a noisy title, like the example above, into a standardized version that matches one of the thousands of curated titles in our taxonomy.
Our analysis shows that the classified title is currently one of the most important features used in our job recommendation engine and significantly improves matching accuracy.
Classifying job titles to taxonomy titles is useful for both aggregating jobs as well as collecting statistics. We’re going to share how we address these issues at ZipRecruiter.
The Taxonomy Title Database
The Taxonomy Title DB is built as a tree and consists of four levels:
1. Industry
2. Field
3. Class
4. Title
The titles are the leaves and contain tens of thousands of entries. The industries are the roots.
A taxonomist maintains the DB manually and updates it with new job titles in the employment market.
Examples of titles in the DB include:

Training data and the bias for generic job titles
The training data is collected from jobs that have a job title that exactly matches a title from the taxonomy. After doing simple cleaning like removing location names, we used a few million job postings. During training we don’t use the title as a feature, just the job description because the title is the label and the model can learn to extract it and not generalize. At inference time, we concatenate the title to the beginning of the job description.
Our taxonomy contains specific job titles such as “CDL Class A Truck Driver”, but also contains more generic titles like ‘Driver’ or ‘Manager’.
Generic titles are useful when dealing with uninformative job descriptions. There are cases in which job descriptions are poorly written and generic titles are the best choice available. However, it turns out that generic titles are also widely used by employers publishing jobs. So we have cases where we get a job title like “Driver,” but when we look into the description we see that the actual title should have been something like ‘CDL Class A Truck Driver’.
Note that in cases like these, the label isn’t actually wrong, it is just not as precise as we need, and since the machine-learned model uses the data to learn, it eventually tends to predict generic titles over specific ones, due to their abundance in the training set.
One approach to deal with this issue is to remove these “generic” entries altogether from training, but that will result in losing valuable training data. Another approach would be to resample the data so that specific labels and generic labels are roughly the same size. This is not easily done, as it’s not always easy to know when a title is actually “generic” and when it can be further refined, and thus more specific.
Our taxonomy is diverse and contains job titles for every field in the employment marketplace, including the many alternate titles that describe the same role. In some industries where we have extensive familiarity with the various roles, we can clearly identify when a title is generic, such as with “driver” jobs in the transportation industry. In some cases we have less familiarity with what employers consider to be a catch-all title. For instance, in the storage industry it is difficult to say whether “lead warehouse supervisor” describes a specific role or if it is generic and may describe any number of different job duties and responsibilities.
When we are unable to clearly make this call, we need a general solution not tailored to specific entries in the taxonomy.
Working on a General Solution
Generally, we use the cross entropy loss function with one-hot encoding for training. It’s defined as
![]()
where p is the predicted class probability and p(y) is 1 for the true label and 0 otherwise.
However, there’s a problem with cross entropy loss. The way it’s formulated gives value only to the one true label, so all other predictions are equally wrong.
While training, we try to optimize the probabilities of all “wrong” predictions toward zero equally. So for this implementation, predicting “Driver” for a “CDL Class A Truck Driver” title is just as bad as predicting ‘Java Software Developer’ for the same job.
Obviously, that eventually favors predicting generic titles over specific ones, as there are more generic titles as labels.
Using Reinforcement Learning
To prevent overfitting on the labels, we use multi-task learning with cross entropy loss and reinforcement learning (RL) loss as is done in Neural Machine Translation.
![]()
The RL loss is the sum of the reward over the classes.
![]()
We used a simple reward function: the word overlap or word precision between the predicted taxonomy title and the job description and the length of the taxonomy title. We assume longer titles mean more specific titles.
As the reward function is not differentiable, we use the REINFORCE algorithm for optimization with gradient descent:
![]()
We estimate the expectation by averaging over only the top k predicted classes.
The RL loss acts as a kind of a regularizer preventing overfitting of the true label. It effectively allows certain classifications to be an “OK” prediction, as they have some relevant words from the job description, even though they’re not necessarily the best (“true”) label.
If we are to use only the RL loss, the model will abuse the reward metric, and will learn to return the longest title with the most common words. Using multi-task learning brings balance between the advantages of both loss functions.
Another great by-product of the RL loss is that the class distribution is actually well calibrated and we were able to use it as a measure of the classifier’s certainty of its own prediction.
The Model
The model is based on fastText. We found it to be a great trade-off between fast inference and relatively good accuracy. It’s a neural network with a randomly initialized word embedding layer and a single linear hidden layer. We used only unigrams.
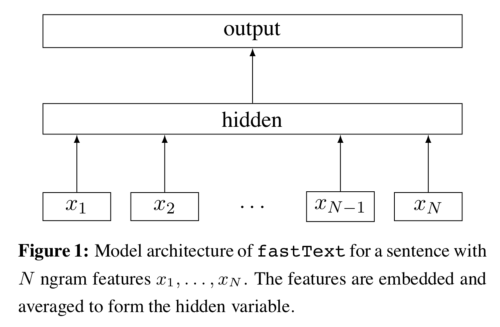
We also found that adding position embeddings was helpful. Every position in the text is represented by a vector in the same dimension as the word embedding and both are combined to obtain a representation that takes word order into account.
Adding word level features like ‘is all upper case’ and ‘is numeric’ also helped for identifying ambiguous acronyms like “IT.” The word level features are added in the same way as the position embeddings, making every combination of features a unique vector.
For the classification we used a similar procedure as in Prototypical Networks to help with the rare titles accuracy. In Prototypical Networks the distribution over the classes is defined with a softmax function of the distance between the class prototype and the network output.
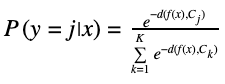
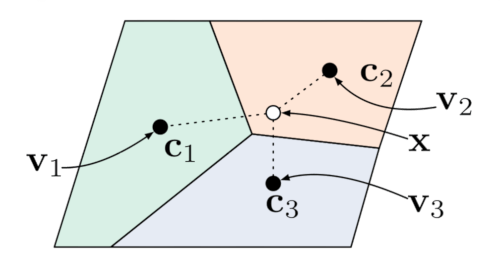
Where f(x) is the output embedding from the model, Cjis the class prototype embedding and d is a distance function. The prototype acts like a cluster center for a class, giving extra information about the class. We have some rare classes in which we have only a few titles as examples.
In these rare cases the network will only overfit on the training data.
The prototypes force the network to converge to a central area which represents the class even with just a few training examples.
We use the average word embedding of the class text from a pre-trained word2vec as the prototype and cosine distance as the distance function.
Below we provide a diagram of the entire model:

Results
We evaluated the model manually on a gold standard with a combination of the taxonomist and crowdsourcing.
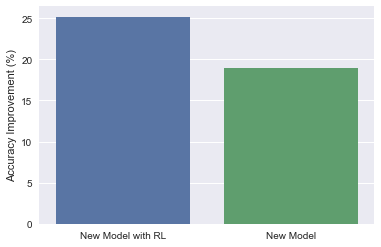
The new model gives about a 20% overall increase in accuracy from our current solution, and the model with RL gives about a 5% increase relative to the same model without RL.
Summary
Using reinforcement learning in the NLP world has led to good results in some use cases. It has also become a common method over the last few years, especially in subfields like machine translation, question answering, and text summarization. With RL, we were able to elevate fine-grained text classification accuracy using a very simple and naive reward function. The approach may be applicable to other classification tasks or other fields as well.
This article shares some insight into the challenges the ZipRecruiter Tech Team works on every day. If you’re interested in finding solutions to problems like these, please visit our Careers page to see open roles.



